This page is used for discussions of the operations and policies of Wikimedia Commons. Recent sections with no replies for 7 days and sections tagged with {{Section resolved|1=--~~~~}} may be archived; for old discussions, see the archives; the latest archive is Commons:Village pump/Archive/2026/03.
Please note:
If you want to ask why unfree/non-commercial material is not allowed at Wikimedia Commons or if you want to suggest that allowing it would be a good thing, please do not comment here. It is probably pointless. One of Wikimedia Commons’ core principles is: "Only free content is allowed." This is a basic rule of the place, as inherent as the NPOV requirement on all Wikipedias.
Any answers you receive here are not legal advice and the responder cannot be held liable for them. If you have legal questions, we can try to help but our answers cannot replace those of a qualified professional (i.e. a lawyer).
Your question will be answered here; please check back regularly. Please do not leave your email address or other contact information, as this page is widely visible across the internet and you are liable to receive spam.
Purposes which do not meet the scope of this page:
For questions about copyright, technical matters, or help that does not relate to the general Commons community as well as proposals, please see the other discussion boards linked in the blue panel at the top.
SpBotarchives all sections tagged with {{Section resolved|1=~~~~}} after 1 day and sections whose most recent comment is older than 7 days.
January 02
History maps of Europe
Latest comment: 1 month ago6 comments4 people in discussion
Hi, I would like to discuss the description in all categories of the scheme "Maps of <country> in the <x>th century" (see for example Italy, Belgium, Spain, Poland). There are three different points about the current system I would like to invite comments on:
the wording of the definition in the first paragraph of the hatnote
whether or not to include "you may also be looking for similar maps" (second and third paragraph) of the description
whether or not to re-include a distinction between history maps (in this category group) vs. old maps (not in this category group)
For the first point, there are two proposals, the first is the current "Maps showing all or most of the territory (geographic area) of modern-day <country> - as the lands were in the 8th century (701-800 CE)" which I would prefer to replace with a simple "This category is about maps of the history of <country> in the 8th century (701-800 CE)", given that "modern-day territories" are not always the same as they were in the respective century. Another critism of mine is that "all or most" excludes history maps that only cover smaller parts of the country in question.
For the second point, my argument is that these paragraphs are not necessary, since the links to the Atlas project should be included in the respective parent category (i.e. "Maps of the history of <country>"), which is also linked via template.
For the third point, I find it essential to point out that Commons has always distinguished "current", "history" and "old" maps, formulated in Template:TFOMC: "history" maps include this map of Poland in the 16th century (created recently, depicting the past) but "old" maps include this 16th-century map of Poland (created to depict the present, back then). There are certain grey areas where these categories DO overlap, especially "old history maps", but in quite many cases they don't. The respective category names are quite similar and can be confused, so I would suggest to mention this right in the category description.
I've put my own opinion in italics to explain why I think this requires debate, but I would like for people to check out the scheme examples for themselves, and judge on their own. Peace, --Enyavar (talk) 08:11, 2 January 2026 (UTC)Reply
@Enyavar: I'm trying to understand the first point. A couple of questions that may help me understand:
Would there be no such thing as "maps of Germany" for any date before 1866? Or would we take "Germany" before that date to mean the German-speaking world (and, if so, would that include areas where the rulers spoke German, but most of their subject did not)? or what? (Similarly for Italy.)
Similarly: would there be no such thing as maps of Poland or Lithuania between 1795 and 1918? If so, what would we call maps of that area in that period?
I could easily provide a dozen similar examples, but answers to those two will at least give me a clue where this proposes to head. - Jmabel ! talk18:49, 2 January 2026 (UTC)Reply
Thanks for that question, our categories about "history of" do not really care for nation states existing. Germany's history begins quite some time before it became a nation in the 19th century, and Polish history did not stop during the times of division: Poland in the 19th century is unquestionably a valid category. Our history categories generally imply that people know the limits of a subject without exact definitions.
Your question is getting to the reason why I am uncomfortable with the current hatnote/definition of these categories. I have not checked for all countries in Europe, but I'm quite confident: We do not define the subject of "Maps of the history of Poland" with a hatnote. We do not define "Poland in the 16th century" either. So why would we define the combination subcategory of the two so narrowly and rigidly, that only 6 out of 26 files currently in the category even match that (unreasonable) definition? (And of course, Poland/16th is just a stand-in here, I would argue the same for Spain/12th and Italy/8th and all others)
I would even be okay with no definition at all, besides a template notice (my third point) that "maps of <country> in Xth century" is about history maps, and old maps have to be found in "Xth-century maps of <country>". --Enyavar (talk) 04:53, 3 January 2026 (UTC)Reply
Please read the original post, that is not a comment on the actual questions of this topic. Old maps are not the topic here, this is about history maps (i.e. Maps showing history of specific countries/centuries) regardless of when they were produced.
In our Commons:WikiProject Postcards we have the similar problem. Is this a "old postcard of the German Empire" or a "Postcard of Germany". There we are mostly agree, that today people often search for postcards be the locations of today. So many former German towns are now Polnish towns and so we are categorized this postcards under the polnish name of the town. See also Commons:WikiProject_Postcards#Categories. Best regards --sk (talk) 12:29, 12 February 2026 (UTC)Reply
February 22
Maps from Our World in Data
Latest comment: 11 days ago30 comments7 people in discussion
A suggestion in regards with the maps from Our World in Data: remove from each map the category <year> maps of the world.
These maps weren't published in the years referenced. In addition, it could make the categories of <year> maps of the world more easy to browse.
As with other files in these categories, that's the year of the data. This categorization has large usefulness to find and update outdated images used on Wikipedia. And the category title does not imply that's the year the map was made. Prototyperspective (talk) 20:13, 22 February 2026 (UTC)Reply
I have been meaning to say something about these maps, and this is a good occasion. User:Universalis is right that these maps were not created in that year, and it IS practice on Commons to understand "<year/decade/century> maps" being the maps created in that timeframe, not the maps showing that timeframe - the latter would be better placed under "maps showing <year/decade/century>".
User:Doc James, who is creating the majority of recent OWiD maps that concern what might be called history, is producing them by the thousand each day, at least as far as I can observe. For 2026-02-24 I just checked and saw 5000 edits, most if not all of them creating and categorizing OWiD statistics/maps usually looking like this (1947), this (1664) and this (1800). That is an enormous output and just for example 1764 maps of North America is currently dominantly OWiD maps and I suspect that this is true for basically all year-maps-of-world/continent right now. Case in point: the categories for 1444 maps of Africa, 1445 maps of Europe or 1446 maps of Asia don't even exist right now, but they are already filled with OWiD maps.
The titles I suggest above are up for debate. Is it more practical to use "Our World in Data maps" or can it be shortened to "OWiD maps" ? Also, should it be "showing" (as per our category branch "maps showing <year>") or should it just be "of" ? --Enyavar (talk) 03:58, 25 February 2026 (UTC)Reply
Sure we can adjust the categories however folks wish. We have additionally build a tool to help with more fined toned mass categorization. See Help:Gadget-CategoryBatchManager.
With respect to numbers, yes have uploaded about 600K so far and it looks like I am maybe a third done, so maybe 1.2 million more to go. Will likely not finish until this fall. Doc James (talk · contribs · email) 06:03, 25 February 2026 (UTC)Reply
and it IS practice on Commons to understand "<year/decade/century> maps" being the maps created in that timeframe, not the maps showing that timeframe this is an inaccurate statement. Look into any of these categories of years of the recent few decades and you'll notice how what you said is false. What you said applies to old maps and there usually the data shown is not known better than year of map made or the same. Prototyperspective (talk) 13:47, 25 February 2026 (UTC)Reply
In 2014, it has been decided that "<year> maps" should essentially be empty disambiguations, and we should use "maps created in <year>" and "maps showing <year>" instead. Practically, this rule has never been enforced, and has lead to many simmering debates ever since. I'm striking my quarrelsome nitpicks from my previous comment, in order to focus on the suggestion at hand: Creating special categories for OWiD maps. Okay? --Enyavar (talk) 11:04, 26 February 2026 (UTC)Reply
Doc James has stated above that we are going to have about ~1'800'000 maps once the current run of creating these files is finished. And I don't even think that will be the end of it. So I agree, we need to have a good standardized cat structure, and I am willing to hear if Doc James also has input on good names, or input on which names are less good. With that lead:
As far as I can see, we do have the following seven regions over which these maps are distributed: "the world", "Africa", "Asia", "Europe", "North America", "Oceania", "South America". These are the seven most common frames I noticed so far, please correct me if there are more. "World" is probably going to be a bit larger, but I don't think we should neglect the other regions, which are all going to be equally densely filled.
Now, thinking about the best name structure. I would prefer to pre-fix the data source, similarly to how we do it with other major map providers like "OpenStreetMap maps of...", "USGS maps of...", "ShakeMaps of earthquakes in...": The most important qualifier gets frontloaded. For easy manual input, I would prefer the name "OWiD maps of...". However, the categories are unlikely to get assigned manually, and it is much easier to understand what the acronym means when it is written out. So right now, I would tend to go with the general Our World in Data maps of... as the prefix, then followed with the seven (?) regions identified above.
Afterwards comes the suffix. Prototypeperspektive suggested ... showing <year> data, my own ideas leaned towards ... in <year> or ... showing <year>. These suggestions all look equally good to me. Prototype's suffix has the advantage of pointing out that these maps are data-driven and not cartography-driven. So I think that would be best.
If the above suggestion seems agreeable... how difficult is it for Doc James to change the automated exports and the templates that are currently in use? And would you be able to do an automated re-categorization of all the already existing files? Would you need help? --Enyavar (talk) 18:54, 28 February 2026 (UTC)Reply
[[:category:Our World in Data maps of <region> showing <year> data]] would be subcategory of [[:category:Our World in Data maps of <region>]], [[:category:Maps showing <year>]] and [[:category:<year> maps of <region>]]. At a later point, I would like to reshape the last of the three parent categories to bring the OWiD maps under the 20th-century/1940s branches of <region>. With the example above, there is currently no sufficient subdivision of Maps of the history of Oceania, but the idea is creating Maps of Oceania in the 20th century and Maps of Oceania in the 1940s, and that would again be a subcategory of Oceania in the 1940s... But I think that work would not affect the OWiD-maps and their templates itself. --Enyavar (talk) 19:13, 28 February 2026 (UTC)Reply
You are currently categorizing them upon upload by two mechanisms, one is the template:Map showing old data, the other is assigning regular categories. Right now, neither of these mechanisms is a bespoke template designed for OWiD content.
I can imagine a template that works like {{OWiD maps showing|Africa|1758}} that would create the categories we contemplated above, including links to skip forward/backward and also links to skip to the other continents/world extent. If we used such a template to create the category framework discussed above, couldn't you adapt your exporting automatism once that exists? I can only image it would take less work later.
Before I attempt working on such a template myself, I'm asking a few users who I suspect have more routine in templating, @Clusternote, AnRo0002, and Reinhard Müller: My question is how you would go about it: templates for the file descriptions; templates for creating these categories; or both? Are there pitfalls I am not aware of? We are talking here about ca. 2 million standardized files ranging from very few around the year 1021 to an abundance of such files for 2021, with hundreds of files per year per continent in 1834 already. The maps are optimized to be used in slider-frames elsewhere; for Commons I'm more concerned with handling the categorization. Thanks in advance! --Enyavar (talk) 21:51, 3 March 2026 (UTC)Reply
As for #2 I would have suggested "... showing the 1940s" and "...showing the 20th-century" as parent categories. But you're right, I talked above about "<year> data" so "<decade>s data" and "...<century> data" would be the logical consequence. Now I'm less sure about the format. I am not married to the idea of requiring the "data" suffix, but as long as the template could be made, I see no real problem. @Prototyperspective: , what do you think about "Our World in Data maps of Oceania showing 20th century data being the respective category on the century level? Enyavar (talk) 19:11, 5 March 2026 (UTC)Reply
The usage of the templates is super easy, no need for any parameters specifying the continent or the year, they take everything they need to know from the name of the category they are used in.
The names of the continents are automatically translated using Wikidata labels. The first part of the title and the text above and below the navigation blocks are just examples. These can be used as an explanation for the category which is centrally maintained and must only be changed once if something should be changed, and if the texts are final, we can also make them translatable.
P.S. Looking at the currently existing category tree about maps, I really think that the OWiD categories shouldn't be in Category:1947 maps of Oceania or Category:1940s maps of Oceania. For centuries, we already have Category:Maps of Oceania in the 20th century, and I think it might be a good opportunity to introduce these categories also on a decade and year level. If you want, I can also create the templates for "Maps by continent and century/decade/year shown". And/or whatever you consider useful for building the correct parent structure for the OWiD categories. --Reinhard Müller (talk) 14:37, 6 March 2026 (UTC)Reply
The decade-template for the world in the 1940s did not work (lua template cannot find "the world"), I hope this can be fixed. Aside from that it looks pretty great. Sorry, two more nitpicks, some links only appear once some other part of the structure has been fully built up. The year-ribbon only shows up once the decade-category is in place; and it seems as if the decade template only shows up once the century-category is in place? Also, I think that the subcategories could be sorted with a space (" ") instead of the "@".
I agree with your proposal that instead of "1947 maps of Oceania" we should have "Maps of Oceania in 1947" which would be the "maps showing"-version. "Maps of Oceania in 1947" would be a subcategory of "Maps showing 1947", "Oceania in 1947", "Maps of Oceania in the 1940s" respectively. This category would then hold the OWiD maps and all maps that show Oceania in 1947 through the historian's lens, similar to how we already have Maps of Poland in the 16th century (see also one thread above...) and Maps of the world in the 1940s.
I fixed "the world" (ooh, it feels good to write this ;-))
It is generally true that the template works best when the categories are created top down (i.e. first the centuries, then the decades, then the years). Still the navigation ribbons should appear even if the parent category does not exist (yet), I will have to investigate why they don't. But for the addition of the correct parent categories for new categories, it is important anyway that the parents pre-exist.
I have (years ago) thought a lot about the question of logical sort keys, currently they are used very inconsistently across commons. I've even made a page summarizing my thoughts which you may or may not agree with. About this specific case, I think the space is widely used for meta categories (Blah blah by xyz) and should be reserved for that, and that the @ has the advantage of being sorted after all the other special characters, so if for example the category key "*" is before the alphanumeric subcategories, it is also before the numeric subcategories if the numeric are sorted as @. In the end I don't think in our case it makes much of a difference as long as all the subcategories use the same key so they are sorted correctly - which is taken care of by the template.
About the "Maps of Oceania in 1947", would you want to also create them right now? Should I create a {{Category description/Maps by continent and year}} (and decade and century), and adapt the OWiD templates to the new parents?
I don't use a bot, and I think that the CategoryBatchManager can add parent categories, but not a template. But since you don't have to change a single letter when copying the template from one category to a similar one, it can be done very fast. --Reinhard Müller (talk) 18:02, 8 March 2026 (UTC)Reply
About the "Maps of Oceania in 1947" - yes, you could create a template for that, as well. We already have parts of that, but right now they were created in a manual fashion: North America/1770s and Asia/18th and Europe/11th. I'm not yet fully eager and ready to apply this structure as long as the other treat about #History maps of Europe is still unresolved. But having the templates prepared now might help later. Once those maps-per-continent-shown-by-year exist, the OWiD template would be switched from "1940s maps of Asia"+"Maps showing the 1940s" --> "Maps of Asia in the 1940s" and so on. --Enyavar (talk) 19:51, 8 March 2026 (UTC)Reply
I have not (yet) changed the parent categories for the OWiD categories. Please just let me know when I should do that.
Also please don't forget that the texts above and below the navigation ribbons are just placeholders (in the OWiD templates and the new templates), and they should be finalized before the templates are widely used. --Reinhard Müller (talk) 22:02, 8 March 2026 (UTC)Reply
Looks great; thanks very much. I just don't know how complete these cats currently are and will be. They could be made complete via deepcategory category intersections and moving files with cat-a-lot. Prototyperspective (talk) 18:22, 9 March 2026 (UTC)Reply
But first, we need to categorize the OWiD maps. I populated the 1940s structure with a few hours of Cat-a-lot, but there is a catch: all these maps currently have the template {{Map showing old data|year=1942}}. For the 1940s alone, removing that template means manually editing 17'500 files. We must use a bot to do these edits, I think. The algorithm, for all ~75'000 maps of Asia would be roughly as follows:
for all files in [[Category:Our World in Data maps of Asia]]
if "{{Map showing old data|year=YYYY}}" occurs in the file:
take the YYYY as a variable to insert "[[Category:Our World in Data maps of Asia showing YYYY data]]" //** a single category for the location and year of the map **//
if that inserted category does not yet exist: create it with "{{Category description/Our World in Data maps by continent and year}}" //** (as helpfully provided by Reinhard)**//
take the file name as the variable topicname and strip File: and , Asia, YYYY.svg (or ,Asia,YYYY.svg) from that variable
if that inserted category does not yet exist: create it with "[[Category:Our World in Data maps by topic]]" //** in many cases, better names might be found, but that cleanup can be handled afterwards manually where needed **//
remove all occurences of "{{Map showing old data|year=YYYY}}", ""[[Category:YYYY maps of Asia]]" and "[[Category:Our World in Data maps of Asia]]"
(else leave the file alone)
repeat the same with "Africa", "Europe", ["North America" or "NorthAmerica" would need to be mapped onto "North America"], "Oceania", and so on.
I do not know how exactly to program a bot, but I think this would do the trick, not only to create and populate the categories for continent-by-year, but also to have distinct categories for each topic. Right now, I don't think the latter exist yet. --Enyavar (talk) 19:51, 8 March 2026 (UTC)Reply
For the 1940s alone, removing that template means manually editing 17'500 files: I haven't been following all of this, but why manually? - Jmabel ! talk20:53, 8 March 2026 (UTC)Reply
True, the bot run would also touch those files. I just wanted to emphasize that so many files cannot be realistically processed manually, and then formulated how I think this could be automated. I struck the word in my earlier response. --Enyavar (talk) 22:21, 8 March 2026 (UTC)Reply
Help needed to close 6,323 Category for Discussion cases
Latest comment: 1 day ago13 comments8 people in discussion
There is a large and growing backlog of open CfDs. It would be great…
if more people would participate in these discussions to move them toward closability and
if more admins or CfD/backlog-experienced users would to go through CfDs to close closable discussions (if there is a way to filter these for discussions with 3+ participants, that would be useful)
CfDs over time – this chart was made possible by generative AI and uses data of scraped from Wayback Machine archives of Category:Categories for discussion via a new tool
The oldest open discussions are from 2015. If you have any ideas how to increase participation or more easily solve more CfDs, please comment. For example, maybe there is a way to see CfDs for subjects one is interested/knowledgable in or users could identify users relevant to CfDs and ping them from there to get these to participate (e.g. top authors of the linked Wikipedia articles identified via XTools).
CfDs shouldn't be closed for the sake of it prematurely though – the reason for why they have been started should really be solved before they're closed – sometimes this requires some restructuring, renaming or categorization work. For info about CfDs, see Commons:Categories for discussion. Prototyperspective (talk) 13:55, 6 March 2026 (UTC)Reply
Perhaps we can categorize CfDs like we categorize DRs, so people who are only interested in a specific subject can browse CfDs relating to that subject more easily. Thanks. Tvpuppy (talk) 15:19, 6 March 2026 (UTC)Reply
Good idea. Joshbaumgartner had already set up Category:Category discussions by topic in mid 2024. However, it can be difficult to categorize CfDs into these as these topic categories probably would need to be and are very broad where deepcategory fails. This probably is part of the reason for why the current subcategories are very incomplete and contain just few CfDs (which means that cat is currently not very useful and also doesn't seem to be used much so far). For example, when trying to find more than the 1 CfD currently in the Culture-related CfDs, this search does not show any CfDs and neither does this search. Prototyperspective (talk) 18:38, 9 March 2026 (UTC)Reply
Indeed, it was an attempt to do exactly that, but as a manual process it isn't going to be useful unless broadly adopted as part of the CfD process and probably needs some better gadgetry to make it user friendly for nominators to categorize their CfD from the start. Josh (talk) 01:11, 10 March 2026 (UTC)Reply
Agree. Adding some functionality to a widely-used gadget or a gadget in general may not be needed for this to be broadly adopted: one could have a bot auto-categorize the CfDs and then then better-populated by topic cat could maybe be made more visible in various ways so more people use these. Since the deepcat queries break, I don't know how that could be done theoretically – maybe via petscan or quarry or the Commons SPARQL query service. Prototyperspective (talk) 12:46, 10 March 2026 (UTC)Reply
I agree that categorizing CfDs could be useful, both for users to find them to comment, and for admins to find them to close. (That's especially true where the discussion hinges on specific knowledge bases, or is conducted in non-English languages.) I don't love the idea of canvassing users, even by neutral/automated criteria, unless it's strictly opt-in.
Like many other tasks, the CfD backlog is mostly due to a shortage of admin time. (Experienced non-admin users can also close discussions, and I think it's a great place to learn admin for those considering the mop, but obviously they are not able to delete categories when needed.) There's also a notable lack of tools to efficiently work with CfDs, which means that the workload for a given CfD is substantially higher than a DR. I can close DRs or process speedies on my phone in a few spare minutes on the bus, but closing CfDs requires my laptop and a longer block of time.
Tool to close CfDs - it should be one click to add {{Cfdh}}, {{Cfdf}}, etc, just like it is with DRs.
Tool to rename all categories in a category tree, and move associated files
Tool to add/remove CfD notices on all categories in a given category tree
There are some other less common but time-consuming CfD closure tasks that would benefit from tools. For example, sometimes we decide to merge two category trees with identical structures but different names, or to upmerge a large swath of categories. Having to work through these can make a single CfD close take hours.
Some of these may exist in some form on enwiki or other wikis, which could reduce the work required from "write from scratch" to "localize to Commons". Given the importance of the CfD process and the limited capacity of volunteer developers, I really think these should be developed and maintained by the WMF. Pi.1415926535 (talk) 20:31, 6 March 2026 (UTC)Reply
Opt-in notifications of CfDs aren't feasible I think – a related idea however would be to maybe post about categories of CfDs on WikiProject pages about that broad subject.
Regarding the shortage of admin time maybe an approach could be to get more sufficiently experienced users to help with closing CfDs. Only a fraction of CfDs involve cat deletion and one can also delete these by renaming the category without leaving a redirect in many of these cases.
More tools for CfDs would be great – or probably CfD-features in existing tools like Twinkle. To your useful list of missing features, I'd add a tool to modify many category pages at once similar to VisualFileChange. I've asked about it at Commons:Village pump/Technical#Editing many categories at once and this could also be used for the add/remove CfD notices on all categories in a given category tree functionality. I'd like to note though that afaik most CfDs are not held back by this but rather by a lack of user input or nobody closing the closable CfDs. Prototyperspective (talk) 14:27, 16 March 2026 (UTC)Reply
Since the thread was started, the backlog has been reduced to 6311 – not much of a change but it's good to see that the direction currently is downward, not further up. Maybe what could help are summaries of the outstanding issues/question for bundles of stale CfDs. However, that probably doesn't scale above a hundred or so CfDs and most CfDs are rather short. A way to connect people knowledgable/interested in a certain topic with open CfDs in that area seems like a better way forward. If CfDs were categorized by broad topic, this would however still require users to proactively go to that category and see if it has any CfDs of interest to them.
Uncategorized files over timeWith the increasingly large numbers of uncategorized files, I think there needs to be some thought and work on how to address this at scale / effectively without consuming so much volunteer time. One idea is to better aid and facilitate uploaders to categorize their files at upload as outlined in Commons talk:WMF support for Commons/Upload Wizard Improvements#Guidance/facilitation of categorization; another idea would be to have tools suggest categories based on file-title, description, metadata, and content, similar to User:Alaexis/Diffusor.
On a related note, ultimately all of this is largely a two-stage process where adding initial category/ies is stage 1 and diffusion into more specific categories is stage 2; categorization can be improved a lot if initial category/ies are set if the one/s set is/are about the main topic/usefulness/uniqueness of the file. Probably both stages need some development.
.
I've created the chart on the right a few days ago using some new tool that I coded with the help of AIs – does somebody know how to get data for between mid 2015 and early 2024 or why there is this quick rise from 2012 to 2015 but a decline by 2024? Prototyperspective (talk) 12:58, 10 March 2026 (UTC)Reply
The "two-stage process" that you describe is certainly helpful, e.g. by using Category:Unidentified by topic, but I am even more proud about files that I can categorize to their final location. In many cases, this might involve creating a new category for a person, of which a Wikipedia article exists in any language. This new category will, initially, most often contain only one file, but it can be inter-wiki-linked to the relevant Wikipedia articles via Wikidata. GLAMorous is a powerful tool, to find uncategorized photos of persons, of which a Wikipedia article exists. Until a suitable bot will be programmed, these photos have to be categorized manually one-by-one, please. NearEMPTiness (talk) 02:29, 11 March 2026 (UTC)Reply
Just my two cents... I think it is the job of the uploader to choose a suitable category/categories. The "penalty" for not doing so, is that an image will remain unnoticed, and is unlikely to be used in a Wikipedia article. Trying to think of a suitable category is a nice way to pass the time, certainly. But we're looking at about 1000 uncategorized images per day, and I consider myself lucky if I can find a category for more than a handful. Regards, MartinD (talk) 20:27, 12 March 2026 (UTC)Reply
If we find 200 volunteers, who will categorise at least 5 files per day, we will proceed faster than the uploaders of uncategorized files, especially if some of the volunteers will do more than 10 files a day. NearEMPTiness (talk) 20:31, 13 March 2026 (UTC)Reply
Good point but there's also good counterpoints to this. These include that 1) many of these files are copyvios or would be good to delete for other reasons (like being blurry) so going over them is useful 2) often, categorization is hard depending on the file so it may need some Commons contributor to cat it properly 3) many of these files were just transferred from Flickr or other sites – these aren't just original content of the uploads so it's not the file creator who failed at that and many of especially these files are quite useful but missing in the cats which is a disadvantage to Commons and in Commons' interest to address.
The aforementioned guidance in the UploadWizard could involve showing the info that the image is less likely / easy to be found and used if there is no proper category set. Prototyperspective (talk) 23:23, 16 March 2026 (UTC)Reply
Yes, I am right now sorting clips of uncategorized weather maps into these by-day categories. Also, when I come across a newspaper file, I add the day category, but I am not aware of any systematic effort to sort newspapers into these categories. The last time I suggested to do so was in 2024, see the full discussion here. I would support this idea, but also suggest getting support from bots if possible. --Enyavar (talk) 17:26, 11 March 2026 (UTC)Reply
Yes, that would be it. I was trying the wrong date formatting, and I could not find an example. Should it be News articles published on 2026-03-11, or just Articles published on 2026-03-11 so it can contain magazine articles, or just Works published on 2026-03-11, to be as broad as possible? Or should news articles be categorized by the day of the event, not the day published? News travelled slower in the past. That way someone looking up a day during the American Civil War would see the events of the day, not a day or two later, when it was published. --RAN (talk) 18:50, 11 March 2026 (UTC)Reply
Should news articles be categorized by the day of the event, not the day published? News travelled slower in the past.
In this case, there should be a category for the day the article is published, and one for the subject the article is about. "Works published on..." would be a suitable parent category with "Articles published on..." being one of its subcats. ReneeWrites (talk) 21:58, 11 March 2026 (UTC)Reply
Re "Works": Here I don't think we need to consider other periodicals, or books. The exact date of publishing is not too relevant with a scientific journal, so I don't think they would need to be categorized by date. The same with monthly periodicals: these are not daily newspapers, and should be categorized by month of appearance, even if they do have a day-date. That means, "Works published on..." (date) is really superfluous in my opinion, and will just lead to more fractures in the category tree. For example, 1876-06-09 is the exact publishing date of Twain's Tom Sawyer, but we do not need a category for "Novels published on 1876-06-09". Rather, "1876 novels" is precise enough, and "1876 books from Chicago" for the 1st edition (year book location-scheme). Ergo: Publications/Works where the publication day really matters, are (daily+weekly) newspapers, but little else. That is, I'm looking at the matter with pre-internet publications in mind. Post-1990 and post-2000, things may be different.
Then, RAN might have mixed two slightly different subjects in the comment above, namely newspaper issues (the full publication, or whole pages) and newspaper clippings (singular news articles). I think these should be approached differently.
I'm strongly supporting the idea of just categorizing newspaper issues only by date of publishing. In the times when news travelled at the speed of horses or sails, the same newspaper issue would contain stories about events that happened weeks and days ago, along with the local news of yesterday and today. Our users just should expect on their own that an earthquake that happened in Chile at a certain date in mid-19th century, would not appear in a London newspaper on the same day. Also, a weekly newspaper would still be filed by date of publication.
That said, a newspaper clipping of just a single story, should instead be categorized by the date of the event that is described in it. For example, 1921-06-22, but not 1921-06-23, despite being taken from a publication of the latter day.
I think that country subcategories will come up sooner than later, so I want to consider them early. That doesn't mean we should create by-day categories single newspapers, of course. But it still means several different patterns could be established, here I'm going for an example: "Newspapers of the United States, 1899-09-14" or "United States newspapers published on 1899-09-14" or "1899-09-14 newspapers of the United States". All three suggestions fit the existing patterns, I would say. My favorite would be the third: "<date> newspapers" and possibly "<date> newspapers of <country>" --Enyavar (talk) 05:19, 12 March 2026 (UTC)Reply
Would you also prepend the country name, as also established with the photos? That would fit the second suggestion in my post above.
Another thing, would you also change the category names of the year? Right now, we have "Newspapers of the United States, 1826" but also 1826 newspapers of the United Kingdom. Once we take on the daily format, the year categories could be changed to "Newspapers of <country> published in 1826", which also has the advantage of more clarity. In that way we could harmonize the two rivalling category structures. (Just a suggestion to ask if someone else sees that need; needs further debate in a CfD.) --Enyavar (talk) 16:26, 12 March 2026 (UTC)Reply
I guess that photos of monuments/buildings that don't change daily don't need to have a visible by-date-category for the photos that depict them.
But newspapers? Hiding media by making the categories inaccessible is the best way for nobody being able to find them. I would think that these new-to-implement newspaper-by-day categories, however the name, should not be hidden. --Enyavar (talk) 14:39, 16 March 2026 (UTC)Reply
I suppose I can add in two date categories for some news articles. The day of the event and the day of publication, if there is no event category. Where there is an event category, just the day of publication. --RAN (talk) 16:50, 19 March 2026 (UTC)Reply
March 14
Blurring NSFW images
Latest comment: 4 hours ago46 comments18 people in discussion
Is there a feature on the Wikimedia Commons that allows people to hide/blur NSFW images (images depicting nudity, gore, etc.)? If not, should we implement such a feature? Some1 (talk) 16:44, 14 March 2026 (UTC)Reply
This is a perennial suggestion. Even if technically feasible, the very large amount of volunteer work needed to tag images, and the vastly cultural and personal ranges of what would be NSFW, make it unlikely to be effective. If there are images you personally do not want to see, the suggestions at en:Help:Options to hide an image should be easy to implement on Commons as well. Pi.1415926535 (talk) 21:56, 14 March 2026 (UTC)Reply
Tagging images would be as easy as adding them to a new 'NSFW' category or the like. And there should be an easier way for editors to hide/blur these images without to log in and mess with the common.js or .cs. Like how Google search has the 'SafeSearch' option that one could turn on to blur explicit images. With all the age verification laws cropping up around the world lately, there is a possibility that one day, the Commons will be affected. It's better to be prepared than to scramble when the time comes. Some1 (talk) 22:08, 14 March 2026 (UTC)Reply
We have 136 million files. Adding this proposed category would require checking every one of them - a workload equivalent to about 1/8 of all edits ever performed on Commons (and about 1/5 performed by humans) - with no actual benefit to Commons. The automated systems used by sites like social media platforms have significant false positive and false negative rates, as well as significant biases introduced by their training sets, and would not be suitable for use here.
Unlike social media sites, Commons users also understand that there is no universal definition of NSFW. It depends massively on cultural norms, personal views and comfort levels, context of individual files, and what those with power wish to designate as "inappropriate" to further their own aims. Things as diverse as nudity, interpersonal acts like sex or kissing, depictions of religious figures, depictions of people, speech and symbols representing certain views, medical imagery, and animal behaviors may be NSFW to some people and not to others. Many governments would wish to designate files showing protests of dissenting views, the existence of LGBTQ+ people, and the existence of disabled people as NSFW because they represent contradictions to their ideology.
As I've written before when this topic came up, there may be some subject areas where an opt-in filter might have definable criteria, a relatively low chance of use for censorship, and a feasible number of files to check. Nazi symbols is a likely example. But those represent a very small subset of anyone's NSFW definitions. There is plenty of Category:Content-control software out there for those who wish to control what they see. Pi.1415926535 (talk) 23:12, 14 March 2026 (UTC)Reply
I think you're letting the perfect become the enemy of the good. There are plenty of files on Commons which any reasonable person would consider NSFW - e.g. photos of human genitalia, images and videos specifically described as pornography, or those Panteleev photos (you know the ones). We don't need to review every single image; simply tagging images which are already in categories which identify it as likely to be objectionable could get us a lot of the way there. Omphalographer (talk) 02:16, 15 March 2026 (UTC)Reply
Your definition of what NSFW would be likely be different from what someone in Dubai would consider NSFW or someone in Singapore. Governments and organizations would want us to put everything related to LGBTQ+ behind a NSFW filter, Israel would consider pro-Palestinian protest images NSFW, etc. Nudity is also a cultural specific matter. Abzeronow (talk) 03:13, 15 March 2026 (UTC)Reply
Easy: The WMF can add an option that allows individual readers/editors to checkmark certain categories they themselves want included in NSFW filter. Some1 (talk) 03:26, 15 March 2026 (UTC)Reply
I think individual opt-in filters would be fine to have. The problem is how to implement this. The thumbnails on gallery pages are requested directly from the media server without a request on the file page content. GPSLeo (talk) 05:36, 15 March 2026 (UTC)Reply
We just deleted a video on order from the Australian internet censorship organization. COM:CENSOR is de facto not in force anymore Trade (talk) 21:53, 23 March 2026 (UTC)Reply
It works with structured data statements but so far not all or most NSFW files have these set
It does not blur NSFL files such as images showing torn open dead human bodies
I'm not sure how it works – I think it would be best if it worked like on reddit where it blurs the file content and that one can see the individual file by clicking on a button on the image
Support improvements to this gadget and making it easily enable via the preferences and then some thoughtful discussion on whether and which additional things could be done (example: making the gadget usable to logged-out readers). Prototyperspective (talk) 16:39, 17 March 2026 (UTC)Reply
Comment This keeps coming up, but we never get a coherent, concrete proposal, or even a good list of the considerations for a system that would support this without imposing censorship on those who do not want it, or a set of options on what we might consider supporting. I'd be very open to a serious discussion on this front, but it is almost impossible to react intelligently to what is little more than a hand-wave. - Jmabel ! talk23:08, 15 March 2026 (UTC)Reply
Comment People often talk about this as if its a technical problem. It really isn't. The moment we start doing this we have to define what is and is not NSFW. Nobody wants to open that can of worms. The technical problems are trivial comparatively. Bawolff (talk) 23:09, 15 March 2026 (UTC)Reply
Comment I don't think anyone has suggested full-out censorship. Even the OP just requested hiding/blurring. But especially the "Search Media" function should be configurable to have personal settings that blur certain images that come up while searching. The image would then only be displayed, when actively clicking on it. Which images would be blurred? All images from the category that you as a user have determined to be nsfw for yourself, for example all media in Category:Human sexuality or category:Violence (if you consider war paintings and pictures of swords as too obscene). --Enyavar (talk) 11:43, 16 March 2026 (UTC)Reply
Makes sense. Currently, category:Violence would be way too broad to be usable for this. Moreover, it would need some sort of caching as the dynamic deepcategory search operator breaks on such large categories. Prototyperspective (talk) 14:00, 16 March 2026 (UTC)Reply
Just directly in those categories or also subcategories. If you include subcategories, to what depth? Like this isn't as simple as you are making it out to be. Bawolff (talk) 18:48, 16 March 2026 (UTC)Reply
This is the main problem: We would need to store huge index lists of these files to not slow down image loading when enabling such filters. GPSLeo (talk) 19:51, 16 March 2026 (UTC)Reply
Honestly, I don't even think that part is that big an issue (or at the very least there are solutions to that problem). The real challenge is coming up with the list in the first place. Bawolff (talk) 15:55, 19 March 2026 (UTC)Reply
Do you have a specific AI system in mind? AI isn't magic, it still requires making decisions about what type of content the AI thinks is gore or genitalia. On top of that AI adds complications by often focusing on the wrong things (e.g. There was a famous AI system to identify NSFW photos that turned out to just be identifying photos where the subject was wearing lipstick). Bawolff (talk) 16:20, 19 March 2026 (UTC)Reply
I will propose a system Media is requested from thumbnail media server sending an id 0 or 1 for safe search on or make it into a binary for selective Each image will be assigned a “rating” or classification as nsfw
a binary table
Gore
Violence
Non sexual depictions of genetailia
Sex
Etc
Etc
Etc
Etc
yes
1
1
1
1
1
1
1
1
no
0
0
0
0
0
0
0
0
Lets say i want to set my preferences as no gore. Violence no genetailia no sex That would become 01000 The server would let violence through like body cam footage Cyberwolf (talk) 16:03, 19 March 2026 (UTC)Reply
You would still have to agree on the scale then. There is no way to do any sort of collaborative rating without deciding on a rubric. Bawolff (talk) 16:48, 19 March 2026 (UTC)Reply
You make the flawed assumption that it has to be perfect. It's not perfect on reddit. It works on reddit. It's used on reddit. It can work here. Your first two examples are not NSFW. And one can readily discuss and refine criteria, types of cases etc or even just let people edit and work with whatever results there is. E.g. which SD depicts are set which is how the gadget currently works. Prototyperspective (talk) 18:17, 19 March 2026 (UTC)Reply
I don't think it has to be perfect, I do think there has to be some shared agreement on the categories or at least a straw man proposal of what the definitions of the categories should be. Eventually people will fight over what should be in which categories, if the definitions of the categories boil down to WP:IDONTLIKEIT, the fighting will just never end. Reddit works by moderators making arbitrary, unappealable decisions. If people want that system, that's fine, but they should actually explicitly propose that. As far as the gadget goes, I'd say its fine if that's what people want but those depict categories are only correlated with what people generally mean by NSFW so I'm not sure people will actually be happy with it as a NSFW filter. In general I don't object to any of these idea so much as object to people hand waving all the details away. I just want people to make specific proposals detailed enough that they could actually in principle be implemented, so that we have something to actually debate the merits over. Bawolff (talk) 18:40, 19 March 2026 (UTC)Reply
I don't think there will be much of an issue. Just define what should be blurred as NSFW and what doesn't. There aren't really any new categories or structured data – basically things already exist and one would only need to decide which to blur when the user turns on some NSFW toggle. Afaik things on reddit are blurred by whole subreddits blurring all posts by default, e.g. Videos of human sexuality would have all its files blurred, and less often are other kinds of posts marked as NSFW by the person posting based generally on common sense (probably <2% is mods tagging posts NSFW retroactively also based on loose common sense). A proposal consists largely of technicalities of how to make blurring files based on user preference possible and secondarily ways to identify which posts to blur where what's currently used by the gadget are a set of structured data tags. If this is implemented, discussion can follow which SD tags to put under NSFW if and how to make it possible to specify exceptions (individual files and files that also have specific SD) and how to tag all the relevant files (most or at least many do not have these SD tags set and they could be set via the categories). Prototyperspective (talk) 21:22, 19 March 2026 (UTC)Reply
A bit of different angle. In Persian Wikipedia, there have been many attempts of abusing NSFW concept (and "think of the children") to censor educational images. To the point of trying to hide the statue of David (!!) or may I show you this entertaining incident where the state TV blurred logo of AS Roma. So I don't have any issue with showing nudity or eroticism or even "porn" as long as it's educational. What do I have issues with is gore. And not old pictures from WWII or Vietnam war, but high resolution videos/pictures of people getting beheaded or dying by ISIS or similar. It makes me physically sick. I don't have an easy solution but I wish those at least get some sort of blur filter like Telegram (or maybe we could reduce the resolution? just thinking out loud). Surely we don't need to see details of someone being beheaded to learn about actions of ISIS? I don't know. Amir (talk) 00:39, 20 March 2026 (UTC)Reply
There are similar categories for places other than continents. There are also some categories that have been defined, like the first one listed here.
The issue is that our terminology "<year> maps" usually means maps produced in the indicated year, not maps showing data for that year. These categories were obviously not produced that 2028. Most of the content of these and similar categories I've looked at show demographic projections, so they don't represent actual data.
So these categories need to be named differently, but how? "Maps of Africa in 2028" wouldn't work, because the data doesn't represent a real situation. Maybe "Maps of Africa showing projected 2028 data"? Something else?
Since some of these have been created already, we might need to look at those to move maps of projected data into different categories.
An extensively populated cat of that type is Category:2050 maps of the world. For non-ancient maps, the year in the cat title refers to the year of the data shown. For ancient maps that's more or less the same as the year the map made. It would be best if the cats for future dates are renamed or if subcategories for these are created. Maps of projections for the future that is now the past or present also need to be considered. You can find many or most, possibly nearly all such files via Category:Future and Category:Prediction (I've added most of these data graphics to these two cats and their respective subcats for maps).
@Auntof6, there is a related discussion above at Commons:Village pump#Maps from Our World in Data. Not sure what is the best solution for future maps, but in the other discussion, they have created specific templates for OWID maps showing past data. Those templates will categorized these maps into a special OWID category under the "YYYY maps of each continent" category (e.g. see Category:1940 maps of Africa).
Perhaps we could try using this solution for these future OWID maps as well, or maybe the templates needs some adjustments for future maps. Thanks. Tvpuppy (talk) 19:44, 17 March 2026 (UTC)Reply
Latest comment: 16 hours ago10 comments4 people in discussion
I dont agree with the move. While 'Midi' can be translated to 'South'. In French it is more usual to use the word 'sud' for South, 'Midi' is more a general term for a region in the south, not a direction. Midi is not used in rail passenger communication. Smiley.toerist (talk) 13:03, 17 March 2026 (UTC)Reply
I simply harmonised the Wikimedia category with the Wikipedia article, where this discussion already took place back in 2010 (see Talk:Brussels-South railway station). Please check WP's naming conventions for Brussels, where it is clearly stated that if an English name exists or it can be easily anglicised, that name should be used. For Brussels' railway stations, the names "Brussels-South", "Brussels-North", "Brussels-Central", etc. were chosen for the sake of neutrality and consistency. All the other variants (e.g. Brussels-Midi, Brussels-Zuid, etc.) are mentioned in the Wikidata entry. Jason Lagos (talk) 13:37, 17 March 2026 (UTC)Reply
Midi is midday and at 12 oclock the sun is in the south. I think we can change the main category, but keep all subcategories. And certainly not change file-names. These refer massively to Midi or Zuid. Functionaly it is the main station. A lot passengera get confused and try to get of at Brussel Central for train connections. The German hauptbahnhof is much clearer.Smiley.toerist (talk) 14:28, 17 March 2026 (UTC)Reply
Thanks for your quick reply. I am well aware of the origin and meaning of "Gare du Midi", as I am myself Brusselian and francophone. ;-) It is true that the name causes some well-known confusion for international passengers, for the reason you mentioned. Again, the point of renaming the category was for consistency with the established conventions on Wikipedia.
Regarding your suggestions, I fully agree with you that we should not rename the files, as that would not make sense.
For the subcategories, I am more neutral, with a preference for moving them as well to match the head category. Would you see any reasons not to?
I would certainly give priority to first changing the station headcategories. The subcategories are less necessary and create a lot of churn. I have lots of images of the South station in my followlist.Smiley.toerist (talk) 10:38, 18 March 2026 (UTC)Reply
Thanks HyperGaruda - I agree. Right now, Category:Train stations in Brussels is a bit of a mess consistency-wise, with some entries named "xxx train station", others "xxx railway station", and others "xxx station", in contradiction to the principle you linked to. Some also use the (less common) Dutch name, instead of the (more common) French one, contrary to WP:NCBRUSSELS. Jason Lagos (talk) 13:24, 19 March 2026 (UTC)Reply
@Smiley.toerist: I am happy to continue the renaming process as I am familiar with these guidelines, as well as the specifics of Brussels' stations (i.e. regular railway stations vs. multimodal hubs requiring a more general "station" name). Ideally, they should match the corresponding WP categories to maintain a harmonised naming system across the project. In any case, creating a lot of "churn" should not hinder progress if the guidelines request it. Jason Lagos (talk) 13:26, 19 March 2026 (UTC)Reply
The churn is not trivial. As you are not yet a trusted user, lots of mutations are marked as to check in my followlist. I have bigg followlist (28.547) as I try to keep track of every file I uploaded. (started in 2008). As I have uploaded a lot Brussels rail pictures, I now have to increase the followlist parameters the last entries from 250 to 500. I want to keep this list clean and have to manualy Mark as checked each file. This takes time and I cant keep up. Would someone please give Jason to status of trusted, so that that there are not massive amounts of to check files? Smiley.toerist (talk) 09:42, 23 March 2026 (UTC)Reply
Neutrality and "Wiki loves Ramadan"
Latest comment: 12 hours ago32 comments20 people in discussion
Hi everyone, am i the only who wonders what presence is given to the competition "Wiki loves Ramadan" by advertising it on the main page and on banners. For our big three competitions, WLM, WLE and WLF i understand such a promotion since their topics are neutral, for WLR i do not understand it. In my mind, there should be a policy of neutrality for main page advertisements and banners. PS: My comment is not about the WLR itself, but about the question if it should be advertised on same level as WLM etc. --Arnd 🇺🇦 (talk) 15:44, 17 March 2026 (UTC)Reply
In fact, I did feel offended. Not exactly for reasons of Christian belief ... but where is "Wiki loves Lent (Fastenzeit, Carême, Quaresima)"? Where is "Wiki loves Easter"? ... or, on a more general scope, "Wiki loves Christianity"? -- Martinus KE (talk) 16:29, 17 March 2026 (UTC)Reply
I don't think there is any reason why we couldn't have a Wiki Loves Lent or Wiki Loves Easter or Wiki Loves Passover or Wiki Loves Holi for more examples. Abzeronow (talk) 03:25, 19 March 2026 (UTC)Reply
I think this is a good call and would suggest that instead the competition/campaign is made broader so as to be about religious practices or religious festivals. Additionally, I find many campaigns like this one slightly problematic since there already is good free media coverage of the subject but lots of other subjects without any such challenges are missing media files with lots of gaps. Prototyperspective (talk) 16:35, 17 March 2026 (UTC)Reply
While Commons is not bound by the RfC linked above, there are good points brought up there. I think one of the best points is that the standard naming "Wiki Loves [X]" implies more of a celebration/preference than the reality of such projects entail. It's really more like "Wiki Documents [X]" (although that wording is perhaps drier than it needs to be -- I don't have a good alternative). "Document Ramadan With Wiki" maybe better. I, too, am uneasy with explicitly religious events advertised to everyone across the project, but appreciate that it's not realistic to disentangle religion and culture, which overlaps in some places more than others. — Rhododendritestalk | 19:20, 17 March 2026 (UTC)Reply
I was aware of that when commenting and here is a RfC about that m:Requests for comment/Wiki Loves X. The (main) issue however is not with the naming but with the campaign topic where a suggested potential action could be to broaden it to religious practices or religious festivals or even religions overall. Prototyperspective (talk) 19:24, 17 March 2026 (UTC)Reply
This particular event is timed to coincide with the month of Ramadan (18 Feb - 19 March this year) - even if the name or description of the campaign were changed, it's still inherently focused on one cultural event. Omphalographer (talk) 22:54, 17 March 2026 (UTC)Reply
I agree that something like this is better language. It also irritates me to no end that it's "wiki loves x": there must be a better way to name that than anthropomorphizing wikis. —Justin (koavf)❤T☮C☺M☯23:17, 17 March 2026 (UTC)Reply
Comment, on a side note, I expect the main page will change to promote Wiki Loves Africa 2026 after Wiki Love Ramadan ends this month. Do you think promoting this event on the main page (which have been done for the last 4 years) have neutrality problems as well, since it only focus on a specific continent? Thanks. Tvpuppy (talk) 00:00, 18 March 2026 (UTC)Reply
I don't think so, other than Wiki Loves Africa, I don't know any other continent-specific campaigns. There are some country-specific campaigns in the past (e.g. Wiki Loves México, Wiki Loves Sudan), and given their smaller scale, it makes sense these have not been promoted in the main page before. Thanks. Tvpuppy (talk) 00:28, 18 March 2026 (UTC)Reply
They are sort of neutral, in a sense they at least pick different subjects. For example, there was Wiki Loves Pride, it was also criticised, but by different groups of users. If they equally represent concepts "loved" by different social groups or cultures, it might be not big issue. MSDN.WhiteKnight (talk) 04:54, 18 March 2026 (UTC)Reply
My vote is clearly against Wiki loves Africa. For Asia, the corresponding campaign is Asian Month, so I'd rather have the Africa campaign also named that way.
Just imagine it the other way round: What amount of protest would be triggered by a campaign called Wiki loves Europe, or even Wiki loves Catholicism? My guess is that the protesters would get quite vocal ...
Sounds like a good idea. I just think the issue is not with the name but with the focus on a narrow subject where the other equivalent subjects do not have such campaigns. One idea would be to have campaigns for these too and not unlikely contributors interested in that could somewhat-readily set them up; another idea would be to broaden the scope so those other subjects can participate too. I don't think a Wiki loves Europe campaign would get much protest and for continents or large territories/regions like that it may make more sense to also run campaigns for equivalent subjects instead of broadening scope so I'd suggest somebody sets sth like that up (eg Wiki loves Europe, Wiki loves European Union, Wiki loves Oceania etc). If there are concerns that we have lots of media about the subject already or that there are no/very few media gaps etc – that applies more to Ramadan where I doubt there's still important media gaps to close when there's a whole campaign about that particular religious practice. Prototyperspective (talk) 13:41, 18 March 2026 (UTC)Reply
This project supports European users very well. Nine out of the ten largest Wikipedias are European, with the exception having been threatened to get shut down because of the use of bots to make it larger. You speak Dutch, as 22 million people do? We have a Wikipedia with 2 million articles for you. You speak Welsh, as a half million do? We have a Wikipedia with a quarter million articles. You speak Hausa, as a 100 million people do? Have a Wikipedia with less than one hundred thousand articles. We have extremely good coverage of Europe, and pretty poor coverage of Africa. But, no, it would be unfair to support Africans in one way if we don't support Europeans in the very same way.--Prosfilaes (talk) 05:51, 19 March 2026 (UTC)Reply
The German chapter also had a campaign Wiki Loves Democracy. We should not make guidelines, who can use this slogan as long as they are within our project scope and values. The question how large and global a campaign has to be, to be featured on the main page, is a different topic. There I think we should have some kind of guideline. GPSLeo (talk) 06:37, 19 March 2026 (UTC)Reply
as a anti-islamist wikimedian, i believe this project is good for getting information from muslim communities. in year passed, muslim people getting more technology and know wikimedia better. we are the ones who bring information to them. i Support this project. yes, it is looking un-neutral, not secular... but in life everything has flaws. modern_primatඞඞඞ ----TALK20:04, 18 March 2026 (UTC)Reply
Support for RoyZuo's idea of "wiki looks at Topic", that is a much more neutral way to communicate what we are doing. "Wiki loves trees" sounds like we are superficial hippies, "wiki looks at trees" is telling that we encourage studying the topic. Not sure if the Wikilove groups can easily rebrand, but I would love it. To encourage people to upload media about sanitation, we can hardly campaign on "Wiki loves sewage".
(That said, I would not be against "wiki loves Easter" or "wiki loves Holi" either, although there are already plenty of Easter images so it is kinda hard to justify promoting it further. "wiki loves Lent", maybe.) --Enyavar (talk) 12:54, 20 March 2026 (UTC)Reply
id agree unsure for what to call it tho. The whole wiki loves is to provide an encouragement that we value the images. But yeah in this case its odd Maybe “commons loves photography of (subject)” Cyberwolf (talk) 12:59, 20 March 2026 (UTC)Reply
I get that keeping the "L" saves a little branding effort, but "Wiki looks at X" sounds contrived. Why not something more descriptive like "Wiki Documents X"? — Huntster (t@c)18:33, 21 March 2026 (UTC)Reply
or we could use a single umbrella term: "wiki media drive" (like blood donation drive). for each different topic simply append it like "wiki media drive - xxx". RoyZuo (talk) 09:08, 22 March 2026 (UTC)Reply
Wiki also loves Folklore etc. This seems to be much more about the subject matter and we, of course, want photos of Ramadan, like all religious festivals. Secretlondon (talk) 07:41, 23 March 2026 (UTC)Reply
Well the discussion about the naming continues. I don't see a big problem with the name – the issue is that the campaign is about one specific religion where there are no campaigns for other religions or it being about religious practices overall; can we now also discuss this please and not just the name? Prototyperspective (talk) 11:36, 23 March 2026 (UTC)Reply
Latest comment: 2 days ago10 comments6 people in discussion
Has anyone found a way to download the highest resolution version of an image from Flickr, when the image is copyright-expired, but "The owner has disabled downloading of their photos"? Andy Mabbett (Pigsonthewing); Talk to Andy; Andy's edits13:20, 19 March 2026 (UTC)Reply
You can try viewing the highest resolution version and find the source URL, hover over the image and hit Ctrl+Shift+C in Chrome. A docked window opens and the highlighted HTML block could reveal the URL. --PantheraLeo1359531 😺 (talk) 17:11, 19 March 2026 (UTC)Reply
Photo → view all sizes → select the highest size → click the right button of your mouse save page as → save complete page → find photo in the uploaded folder. Does it help? Юрий Д.К.13:41, 20 March 2026 (UTC)Reply
Archive today was using users ips to launch a ddos attack. It’s a security risk. The webmaster tried to generate ai porn of a blogger and extortion him with it from ars technica Archive.today maintainer sent threatsPatokallio told Ars today that he is pleased by the Wikipedia community’s decision. “I’m glad the Wikipedia community has come to a clear consensus, and I hope this inspires the Wikimedia Foundation to look into creating its own archival service,” he told us.In emails sent to Patokallio after the DDoS began, “Nora” from Archive.today threatened to create a public association between Patokallio’s name and AI porn and to create a gay dating app with Patokallio’s name. These threats were discussed by Wikipedia editors in their deliberations over whether to blacklist Archive.today, and then editors noticed that Patokallio’s name had been inserted into some Archive.today captures of webpages.“Honestly, I’m kind of in shock,” one editor wrote. “Just to make sure I’m understanding the implications of this: we have good reason to believe that the archive.today operator has tampered with the content of their archives, in a manner that suggests they were trying to further their position against the person they are in dispute with???” End quote. If this doesn’t justify a full cleansing of it here I don’t know what does Cyberwolf (talk) 15:28, 19 March 2026 (UTC)Reply
If I'm not mistaken one can readily edit that template. You could remove the link and see if somebody complains. I think one archive link is enough but as said I don't know much about IA YT archiving. Prototyperspective (talk) 18:19, 19 March 2026 (UTC)Reply
+1. The vast majority of archive.today links from this template simply land on a useless "no results" page anyway, as the site does not archive content without an explicit request to do so. Can someone please mark this template for translation so that we can start rolling out this change? Omphalographer (talk) 21:26, 19 March 2026 (UTC)Reply
Everything archive.today is accused of is very convenient for creating moral panic. But in reality it doesn't even come close to outweighing its benefits. We don't have enough archive services to throw them away. There are many websites that aren't preserved in other archives. Or that even don't preserve properly in other archives. Pages with embedded posts or other complicated features often are not saved (properly or at all) in Wayback Machine, but are saved in archive.today. Blindly removing links to archive.today would create a great harm to the project. Sneeuwschaap (talk) 00:55, 22 March 2026 (UTC)Reply
You are right, in the particular case of YouTube videos Wayback Machine is better than Archive.today. It saves not only descriptions, but sometimes even the videos themselves. Sneeuwschaap (talk) 23:26, 22 March 2026 (UTC)Reply
I appreciate the desire to archive for future reference, but relying on a site that has shown a willingness to co-opt users' systems to attack others is beyond irresponsible. Archive.today and related sites need to be blacklisted. — Huntster (t@c)13:39, 22 March 2026 (UTC)Reply
Maybe, current manager of Archive.today can be somewhat mentally unstable. Nevertheless, the service works for 14 years. And in the first years it automatically archived all links which appeared in various language versions of Wikipedia. And it contains many archives of currently dead pages which were not saved by other services. And for many websites it is incomparably better than other archives. Does the co-opting users' systems for attacks continue till now? Last time when I have read about it, the site was said to send requests with the interval of 50 minutes — in other words, practically never. Evidently, this is/was a temporary stupidity, triggered by an attempt of doxing of the site owner. Such stupidities are very convenient for criticizing and inevitably cause a moral panic, but in reality they are negligible compared to benefits of the service. Sneeuwschaap (talk) 23:26, 22 March 2026 (UTC)Reply
I think you are confusing a "moral panic" for a "moral reckoning". Moral panic implies that there is not actually an issue at the heart of the community's concern. There is absolutely an issue here, and it's much more than a "temporary stupidity". The developer of the archive leveraged its widespread use to aim a DDOS attack at someone they dislike, threatened to change information in the archive in order to slander perceived enemies, and has basically been throwing a fit since this became public knowledge. We underestimate the damage done at our own peril. Honestly, we should never have allowed such a tenuous and legally dubious archive service to become so essential to any Wiki project; we should've seen something like this coming from a mile away. 19h00s (talk) 23:36, 22 March 2026 (UTC)Reply
Reckoning must be rational, not moral. The fact is that the service has been providing verifiability of many sources for many years. In many cases, with no alternatives. With no evidence of harm to the users. And with no evidence of change of information on any archived pages which have realistic educational value. Throwing a fit and threats of creating a public association between a doxer's name and a porn are very terrible, but are not relevant to the case. Sooner or later the doxing-triggered scandal will end, but the archive service will remain. Sneeuwschaap (talk) 19:57, 23 March 2026 (UTC)Reply
This is not moral panic. I’m not sure what you are talking about. The webmaster created revenge porn (which in the us is a crime in all 50 states) of his critics. Which is unacceptable. This is not moral panic Cyberwolf (talk) 12:37, 23 March 2026 (UTC)Reply
You clearly didn’t read the article i sent and my reasoning. He has no morals “Moral panic” No? There is a ocean sized line between right and wrong It is wrong to use your users on your website without their knowledge to commit an cyberattack You put users at risk for service termination. It is wrong to create ai porn of someone to attack them (crime in the eu and the us) Your defense crumbled already give up The internet doesn’t forget Archive today’s trust is 0 it doesn’t matter the functionality of the website. It matters that the webmaster used Wikipedia and others to funnel people into his cyberattack The archivetoday links are gone Cyberwolf (talk) 15:43, 23 March 2026 (UTC)Reply
In discussions in encyclopedic projects, I prefer to think in other categories than "defense", "crumbled", "give up" and other war-related stuff. Also, I prefer not to stretch my replies with multiple line breaks to fill the entire screen. Also, statements are normally confirmed by links. Especially accusations like "created revenge porn". Sneeuwschaap (talk) 19:57, 23 March 2026 (UTC)Reply
Dan Breen: wrongly identified
Latest comment: 4 days ago3 comments2 people in discussion
The image File:Dan_Breen, circa 1920s.jpg refers. It appears on the en:Dan Breen article (a deceased Irish republican). The provenance is RTÉ, Ireland's national broadcaster, and I have asked them about it.
That Talk page has an item from a relative of Breen informing us that this image is not of Dan Breen but his younger brother Laurence "Lar" Breen, an Irish republican himself. I emailed this Mr O Riain as follows:
It came from RTÉ but the page in question is no longer available: https://www.rte.ie/news/2021/1129/1263845-the-treaty-debate-a-close-run-thing/
Can I ask how you know that this pic is of Laurence and not Dan? Fwiw, I suspect you are correct, for while there is a resemblance, it does not appear to be the same person.
While I'm not an administrator on Wikipedia, if there is any photographic evidence you can send me or point me to in order to prove that a mistake has been made, I will try and pass it on.
Reply: "I am delighted to hear from you, I've had to raise this issue with a number of people over recent years. The reason I am so sure about this that I happen to be a Grandnephew of both Dan and Laurence Breen. Their Brother Patrick Breen was my Grandfather and his daughter Josephine Breen was my Mother. I regret to say I don't have another photo of Laurence Breen(He died in the USA in 1940).
Paud Ó Riain"
What is the best way forward? I am happy to receive a message or messages about this.
Latest comment: 9 hours ago6 comments4 people in discussion
Are there any plans to detect images of text, and automatically run OCR on them, and add the text to the entry? We have lots of news articles without the text, and captions on news images that have not been transcribed. RAN (talk) 18:28, 19 March 2026 (UTC)Reply
Someone showed me (maybe you!) ocr-test.wmcloud.org a few month's ago. It is amazing. Newspaper.com has done a terrible job with OCR so has the New York Times. Ones that were unreadable from both, have been 95% corrected using wmcloud. I am rerunning all the ones that were not readable through again and migrating the text to Wikisource. I just read that Newspapers.com is rerunning all their OCR again using a new AI-OCR. --RAN (talk) 22:42, 20 March 2026 (UTC)Reply
I more familiar with JPG/PNGs because I work with them, so there is my interest. I imagine the pdfs can be run through Adobe and have the text mapped. --RAN (talk) 16:32, 23 March 2026 (UTC)Reply
Office action: Removal of file
Latest comment: 1 day ago28 comments15 people in discussion
This video consisted of security camera footage of a graphic murder, reuploaded from a shock site. It was not in educational use on the Wikimedia projects. The video title suggested that its creator (on the origin site) may have originally attempted to link the violence to illegal immigration, but there was no evidence of it actually being used as political speech.
Our preferred approach is to first give community members an opportunity to evaluate content under your own policies, e.g. COM:EDUSE, but circumstances didn’t permit that in this specific and thankfully very rare case. In the future, we will endeavour to ensure the regulator understands and can accommodate that kind of community governance.
While removing the footage in this case seems like the obvious choice, given its lack of use in articles and very questionable educational value, it does raise questions about the place of other footage on Commons that graphically depicts recent murders whose value isn't necessarily so clear-cut. A pertinent example is File:Hamas members attacking civilians in Kibbutz Mefalsim, Israel (October 2023).webm, showing a man (with his face blurred) killed by being shot in the head at close range and subsequently profusely bleeding after falling to the ground. This file was kept after a deletion discussion due to the widespread view that the footage was public domain due to being CCTV Commons:Deletion requests/File:Hamas members attacking civilians in Kibbutz Mefalsim, Israel (October 2023).webm, and is now used in over 20 Wikipedia articles in over a dozen language versions. If the Australian government had requested that this file had been deleted instead, would the WMF reaction have been different? Should footage like this be hosted on Commons to begin with? Hemiauchenia (talk) 23:26, 19 March 2026 (UTC)Reply
I'm personally curious why the Australian government thinks they have jurisdiction over a CCTV video taken from the US. For transparency reasons, I would also love to see documentation of their reasons for the takedown. Abzeronow (talk) 03:34, 20 March 2026 (UTC)Reply
It's because the material on Wikimedia is published/viewed in Australia. The government of a country rules what is published or otherwise happens in that country. Commons often deals with matters of copyright, which is special because treaties establish a fiction that, in matters of copyright, material on the internet is deemed published in the country of the server, which is why Wikimedia often ignores copyright other than the U.S. (It's more complex. Also, courts have found ways to circumvent that by using tort laws.) But in matters other than copyright, there is no such fiction and the normal principle remains. It is then a matter of the ways by which the country enforces its laws. If nothing else works, it can require the service providers to block access. -- Asclepias (talk) 14:08, 20 March 2026 (UTC)Reply
If this is a particular case in that the Australian government ordered the takedown just because it could be viewed in the country, then the file should be restored as Wikimedia should not be bowing to censorship requests from any government. If it is a case that an Australian national or an Australian affiliate would face legal troubles if not removed, then obviously that is a defensible takedown. It would still be reprehensible behavior from Australia's government but then I wouldn't think in that case that restoration would be right. So we should have more details about the reasons for the takedown so this doesn't seem like WMF meekly acquiescing to a tyranny, which would have a chilling effect on the speech of Wikimedia. Abzeronow (talk) 03:33, 21 March 2026 (UTC)Reply
It's certain that the Australian body required the removal of the video because it could be viewed in Australia. See section 109(1)(c) of the Act: "(c) the material can be accessed by end-users in Australia". The other conditions of section 109(1) also apply. "(a) material is, or has been, provided on [...] a designated internet service" (""service" includes a website" per the definition in section 5 of the Act). And ""(b) the Commissioner is satisfied that the material is or was class 1 material". The Commissioner was likely satisfied since at least a one-minute video of the matter was banned by the Australian Classification Board on 29 September 2025 in the case number "esafety INV-2025-05602". In a FOIA release (see at the bottom of this pdf), the specific reasons are redacted. The unredacted part of the decision merely quotes the criteria from the classification scheme. In short, the relevant part is likely that it depicts "cruelty, violence or revolting or abhorrent phenomena in such a way that they offend against the standards of morality, decency and propriety generally accepted by reasonable adults". The Wikimedia version of the video was 5 minutes. With that, the Commissioner likely gave Wikimedia a "removal notice" per section 109 of the Act. So, at least, we can guess reasonably that that was the context. From there, the WMF, applying its policy, apparently evaluated that there were risks. As you say, absolutely, the WMF should give more details.
Asclepias, so if the UAE complains about Category:Alcohol advertisements everything in that category will be oversighted? I agree with Abzeronow. If any country takes issue with content on Wikimedia that is legal in the US and which the community refuses to remove, that country will have to filter their own internet (and several do). - Alexis Jazzping plz03:47, 21 March 2026 (UTC)Reply
So if Iran demanded Commons to take down highly illegal "Zionist Imperialist propaganda" would Commons obey that as well? Trade (talk) 17:52, 21 March 2026 (UTC)Reply
A request from the w:Australian government! So errr it came from w:Anthony Albanese personally? Since you're not mentioning any particular department or subdivision.. WMFOffice, so why exactly was the file deleted? Was it a copyright violation? Seems unlikely, you have no reason to take that down without a DMCA takedown request, which the Australian government probably didn't file. Did it fail COM:EDUCATIONAL? Who knows, but if WMFOffice were to start vetoing community decisions we'd have a serious problem. Did the file violate some US COM:PERSONALITY right? If that was the issue, you'd have told us. Did this particular video end up on w:en:List of films banned in Australia which states the sale, distribution, public exhibition and/or importation of RC material is a criminal offense punishable by a fine up to A$687,500 and/or up to 10 years imprisonment. Such penalties do not apply to individuals, but rather individuals responsible for and/or corporations distributing or exhibiting such films to a wider audience? In 2025 they banned "Videos featuring deaths of Charlie Kirk, Iryna Zarutska and Chandra Nagamallaiah". So I guess File:Charlie Kirk Assassination View.webm (NSFW) was maybe illegal in Australia (they banned two particular clips, I don't know which ones, and the ban for the clips of Kirk was later lifted) Barrister is the UK/NZ/Ireland/Australia term for lawyer. But the user page of the uploader doesn't seem to declare their country of residence. If this is the reason, how did the AU government work out that Illegitimate Barrister fell under their jurisdiction? Is this why Legal is so vague, because they can't disseminate personal info? Or is this just coincidence? This would explain why the upload log was scrubbed though. Edit: what was I thinking, linking to their enwiki upload log?? Our attorneys determined that the order applied to the Foundation under our policy for determining applicable law. That doesn't mean anything, does it? but circumstances didn’t permit that in this specific and thankfully very rare case. I know you think you're explaining yourself but you're really not. we ask that you not reinstate the file and instead address questions to the Legal team via email, at legal@wikimedia.org. Directing questions to your email (which will simply be answered with "we can't talk about that" - been there, done that) is just a transparency pretense. If the reason is what I think it is, I'd have preferred a notice from WMFOffice like: "We deleted File:An illegal Cuban migrant beheads a motel owner in Dallas, Texas (10 September 2025).webm in response to a request from authorities to reduce the exposure of the uploader and local Wikimedia chapters to legal consequences. This is an office action, do not reinstate" - Alexis Jazzping plz05:33, 20 March 2026 (UTC)Reply
I'm wondering if it was from the eSafety Commissioner (eSafety)? This page highlights what is illegal and restricted but why just this file? There are others here that fail eSafety's illegal and restricted online content classes (1 and 2). The vagueness from the WMF leaves us with more questions than answers.
I'm certainly not saying this file should have been kept, but I just find it odd for a foreign government to get involved with something that didn't happen within that country, nor hosted there. This is a concern as what other content could be treated like this? The files (photographs/videos) from the wars that are currently happening overseas next? Bidgee (talk) 12:00, 20 March 2026 (UTC)Reply
" but I just find it odd for a foreign government to get involved with something that didn't happen within that country, nor hosted there." Why not? If Commons obeys the order then there is literally any reason for them not to do that Trade (talk) 17:53, 21 March 2026 (UTC)Reply
It likely has to do with something like this, or more generally this. I'm guessing the WMF received something like a removal notice described there and that, according to their policy, the WMF considered that there might be "risks of project blocking [...] and/or monetary risks" in case of non-compliance. The Australian document hints that compliance can be required within 24 hours of the notice, which may be what the WMF alludes to by "circumstances didn’t permit". -- Asclepias (talk) 12:34, 20 March 2026 (UTC)Reply
As much as i never want to view these files, it does seem like NSFL files can sometimes serve an educational purpose, more so if they are documenting an atrocity that people deny happened. Bawolff (talk) 15:52, 20 March 2026 (UTC)Reply
It stands for "Not safe for life". Sometimes its used as a term for images you don't want to look at because they are disturbing or violent or something else other than sexually explicit vs NSFW which commonly means the image is pornographic. Bawolff (talk) 20:50, 20 March 2026 (UTC)Reply
It's objectionable how large that educational value is and whether it outweighs the problems of the file. Specifically, I think such files are much more likely for the value/benefits/plausible-use to outweigh the issues if things in the area #Blurring NSFW images are implemented/improved so that one does not accidentally stumble upon such videos (or even autoplaying gifs) and maybe doesn't see it without first unblurring.
I think it has already been mentioned that the file could be renamed if the title was found to be inaccurate or missing important info or otherwise inappropriate. Prototyperspective (talk) 11:03, 22 March 2026 (UTC)Reply
How does only showing the video when explicitly requested protect the personality rights of the people depicted in the video? GPSLeo (talk) 11:50, 22 March 2026 (UTC)Reply
Fair point but misaddressed to my comment to which this issue/point does not really relate. Instead of addressing this in detail or arguing in one way or another, I'd just like to note that there's all kinds of war photography and -videos that document the horrors of wars as well as war crimes that depict dead people as well as people getting killed on Commons. Prototyperspective (talk) 12:50, 22 March 2026 (UTC)Reply
But we only should host these files if they do not violate the rights of anyone. This means that in many cases we can only host a partially blurred version anyways. That we might want to save the original version to make it available in some decades, when they are old enough, has the same challenges as undeletion when copyright expires. GPSLeo (talk) 13:20, 22 March 2026 (UTC)Reply
Like the inflammatory title or not but this is very clearly a relevant file depicting a highly publicised and notable event. This could severely harm our ability to host CCTV files of high-profile crimes --Trade (talk) 17:42, 21 March 2026 (UTC)Reply
Per Commons:License review#Instructions for reviewers, it states "reviewers may not review their own uploads unless the account is an approved bot...Reviews by image-reviewers on their own uploads will be considered invalid.". Perhaps I am missing something, since I understand the user is an admin here and also a VRT member, so maybe there is an exception to this restriction for admins and VRT members?
Fortunately, the license of the files I checked appears to be valid, and I trust the licenses were reviewed by DarwIn correctly, so I don't think there should be any files that needed to be deleted. The issue is just that possibly the license review on these files are invalid.
Not sure how many files are affected by this issue, but I think there is potentially a lot, since a quick search seems to show the user has reviewed more than a thousand videos. This is why I am asking here for advice on what to do. Thanks. Tvpuppy (talk) 02:56, 21 March 2026 (UTC)Reply
I suppose someone could go through and re-review them. I am not volunteering.
I can see keeping these high-level categories for things that relate specifically to a phase of life--people at senior centers, for example, or an over-60 athletic event--but if we are going to categorize known, named individuals by their age, we should straight-out categorize them by their age in years, not a designation like "old." - Jmabel ! talk21:44, 21 March 2026 (UTC)Reply
I think categories about people should be plain, not categorized categories. All information can be retrieved from Wikidata without having the inaccuracies our category system creates. GPSLeo (talk) 08:57, 22 March 2026 (UTC)Reply
I don't know what you refer to with "All information" but there's many things regarding people not on Wikidata that is available on Commons. Then even for those things available in Wikidata, it's not always set by the Wikidata infobox so one would need to request some change to it to have it add a category. Then not all people files have their own category to begin with. Lastly, even for those cases where the files are in a dedicated category with a linked Wikidata item, the item's data is often very incomplete. Prototyperspective (talk) 10:54, 22 March 2026 (UTC)Reply
March 22
Global ban for Faster than Thunder
Latest comment: 2 days ago1 comment1 person in discussion
For photographs, the best way to do that is via {{Taken on}}, not an explicit category. And, either way, a bot won't be able to pick a category by location and date, which is what we typically want (at different degrees of granularity for location in various parts of the world). - Jmabel ! talk22:23, 22 March 2026 (UTC)Reply
"Taken on" is a template for photographs and places files in the "Photographs taken on [date]" categories. News articles would need their own template, although it could be a derivative of the "taken on" template with some slight adjustments. ReneeWrites (talk) 12:30, 23 March 2026 (UTC)Reply
Latest comment: 20 hours ago3 comments3 people in discussion
Currently disambiguation categories say: "This category page should not hold any files." but most disambiguation categories do contain files because there are images and news articles that cannot be disambiguated without more information. There may be a John Smith in a news article/image, but no clue as to which John Smith. Should the warning mention that any images in the category need further disambiguation? I want to make sure people do not remove the files because of the wording. RAN (talk) 20:53, 22 March 2026 (UTC)Reply
All of those files in disambiguation categories are problems waiting to be solved, and clear out the disambiguation category. But perhaps a rewording about should be diffused to zero or some such might be more appropriate. - Jmabel ! talk22:25, 22 March 2026 (UTC)Reply
Latest comment: 4 hours ago5 comments4 people in discussion
I recently used Nero AI denoiser and the results are a bit hyper-real and there is a certain "lie factor". I wonder if there are any guidelines on the use of such tools - should the manipulations be documented as part of the image description? If so what are the essentials? I think keeping the original also on Commons might be a good guideline. Thoughts suggested by this. Shyamal L.03:45, 23 March 2026 (UTC)Reply




_cases_over_time_on_commons.png)
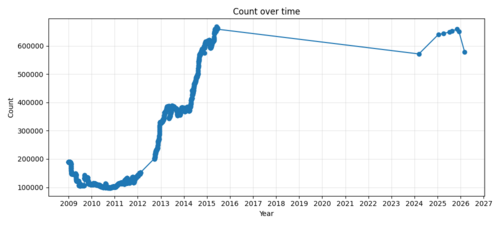
 Oppose. We can't cater to everyone. What if my workplace was at the Taliban? See COM:CENSOR. — 🇺🇦Jeff G. ツ please ping or talk to me🇺🇦 22:53, 14 March 2026 (UTC)
Oppose. We can't cater to everyone. What if my workplace was at the Taliban? See COM:CENSOR. — 🇺🇦Jeff G. ツ please ping or talk to me🇺🇦 22:53, 14 March 2026 (UTC)
 Support improvements to this gadget and making it easily enable via the preferences and then some thoughtful discussion on whether and which additional things could be done (example: making the gadget usable to logged-out readers). Prototyperspective (talk) 16:39, 17 March 2026 (UTC)
Support improvements to this gadget and making it easily enable via the preferences and then some thoughtful discussion on whether and which additional things could be done (example: making the gadget usable to logged-out readers). Prototyperspective (talk) 16:39, 17 March 2026 (UTC).svg.png) Comment This keeps coming up, but we never get a coherent, concrete proposal, or even a good list of the considerations for a system that would support this without imposing censorship on those who do not want it, or a set of options on what we might consider supporting. I'd be very open to a serious discussion on this front, but it is almost impossible to react intelligently to what is little more than a hand-wave. - Jmabel ! talk 23:08, 15 March 2026 (UTC)
Comment This keeps coming up, but we never get a coherent, concrete proposal, or even a good list of the considerations for a system that would support this without imposing censorship on those who do not want it, or a set of options on what we might consider supporting. I'd be very open to a serious discussion on this front, but it is almost impossible to react intelligently to what is little more than a hand-wave. - Jmabel ! talk 23:08, 15 March 2026 (UTC)_berlin_09.jpg)
{kind=link}
{kind=link}